

The technical aspects of a website and the terms associated with it can be extremely confusing. They can also impact your SEO. Some SEO errors require the help of a website developer, but there are issues that a layman marketer can fix with just a little know-how.
4XX errors. Http to Https links. These are the type of back end SEO mistakes that make most marketers quake in their boots.
Don’t be scared off by the jargon, however. Once you understand what some of the terms mean, you begin to understand how they make your website function and why search engines value a website that is clear of these faults.

Let’s take a look at some data that shows which type of errors appear most frequently on websites, and how you can use a report from SEMrush to correct them.
It’s not just geek-speak. It’s user experience.
These website errors are essentially performance issues. They impact user experience, which is the overall experience of a person using your website, including how easy or pleasing it is to use.
If a link is broken, for example, or a meta description isn’t included and won’t reveal what a page is about in search engine results, it becomes a poor user experience. This article from Moz sums it up:
“Usability and user experience are second order influences on search engine ranking success. They provide an indirect but measurable benefit to a site’s external popularity, which the engines can then interpret as a signal of higher quality. This is called the “no one likes to link to a crummy site” phenomenon.”
What types of technical issues can hamper your site’s usability?
One tool which allows you to diagnose website issues is SEMrush’s site audit. The tool crawls through your site, replicating search engine meta-crawlers. It then produces a report which helps you identify errors on your website.
We performed an audit of seven different websites, with individual site traffic ranging from 3,000 to 30,000 visits per month. We then compiled all the errors, and calculated which error had the highest rates of occurrence.
Note that this is entirely a qualitative report. One of these sites may have skewed the overall results, as it may have a large number of one specific issue. But we found these types of errors were largely consistent with each site.
This chart lists the types of errors; their respective percentage of the overall errors; and then if it is a do-it-yourself fix or requires a developer.
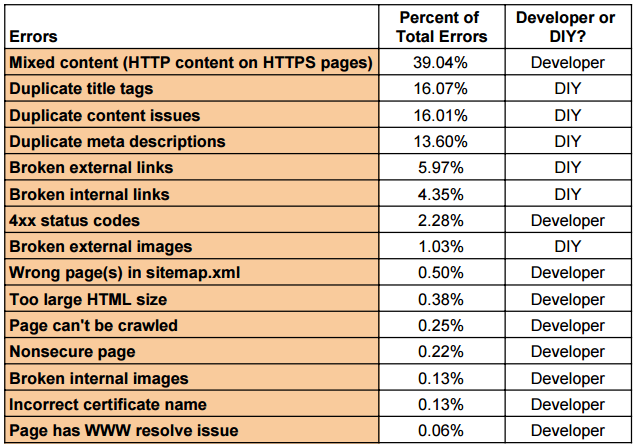
We found that 57% of SEMrush’s errors are what we consider DIY fixes (we’ll show you how to fix them below).
Of the remaining 42%, a whopping 39% had to do with a mixed content error, in which HTTP content was used on HTTPS pages. (We’ll explain that below.) That’s a relatively quick fix that your developer can handle.
So with some DIY work and what should be some speedy resolution from the developer, 96% of the errors could be resolved! Obviously this doesn’t apply to every site, but it’s significant that in these particular cases, a majority of the SEO technical issues can be easily identified and quickly resolved.

Layman vs. developer
We’re breaking the errors down into two categories:

This is for the layman, who has access to the CMS dashboard, pages, posts, etc, but isn’t well versed in HTML or dealing with programming issues.
These types of mistakes aren’t necessarily hard — such as missing ALT attributes or duplicate meta descriptions — but as Elena Terenteva of SEMrush tells us, the problem is the volume of errors.
She notes that a generous amount of mistakes on any website are relatively harmless but very common. “All these mistakes are hard to fix because of their amount,” she said.
It’s wise to focus on changes that should be grounded and reasonable. For example, there is no need to fix missing ALT attributes or duplicate meta descriptions if your site is closed from indexing.

This is where you’ll need to get a web developer involved. Typically there will be some coding changes required or manipulating of program files. Yikes!
SEMrush put together a similar post on the crawlability of your site, which talks about user experience from the search engine perspective (strange to say, but they are users too). It’s a great read for your developer or if you’re more technically inclined.
DIY – SEO errors you can fix yourself
Now that you have a sense of the type of errors that are out there, let’s start with a breakout of SEO errors that the layman marketer can fix.
You’ll need access to your website’s content management system (CMS) to address these problems. We’ll give you an example of how to fix them using WordPress’s SEO Yoast. A different CMS should have an equivalent fix, but you may need to tap the expertise of your developer.

1. Duplicate content issues
Webpages are considered duplicate if they contain identical or nearly identical content. If you have the same content on two or more different pages throughout your site, the search engines don’t know which page should rank.
Duplicate content traditionally has been a “black-hat” tactic used to drive higher rankings, and Google will flag you for it.
Many times, however, the error is unintentional. In a CMS, the taxonomies for your categories and tags may not be set up correctly, so the search crawler interprets it as duplicate.
Solution: First and foremost, write original content for your website pages. You may borrow blocks of content for consistent messaging from different pages, but by and large, each page should be different.
In WordPress, if you don’t have the settings adjusted to “No Index, Follow” for your category and tagged pages, they can show up as duplicate content.
NOTE: This could also be the cause of duplicate title Tags and duplicate Meta Description errors. Fix this error first, as it could reduce your other “duplicate” errors.
To avoid the duplicate Tag and Categories issues in WordPress, you will have to adjust a setting in the WordPress taxonomy.
Go to your WordPress dashboard, and select the Yoast SEO option on the left-hand toolbar. Then select Titles and Metas, and be sure to indicate “No Index, Follow.” This will alert search engines this is not a page to be indexed by the search engine’s crawlers.
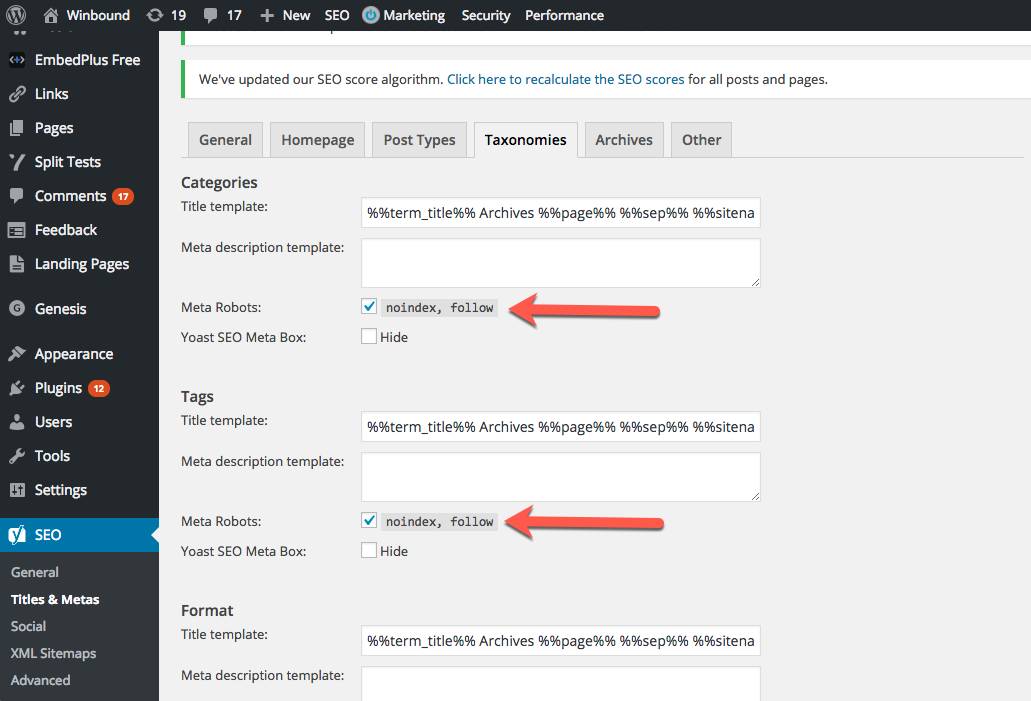
If you’re not on WordPress, you may have to consult with your web developer to avoid the Tag, Categories issue.
As we mentioned, you can generally avoid duplicate content issues by providing unique content on each page of the site. If, for some reason, you have to provide an exact duplicate page (multiple product pages, for example), you can use a “canonical tag” on the duplicate page, which will let Google know where the original page is.
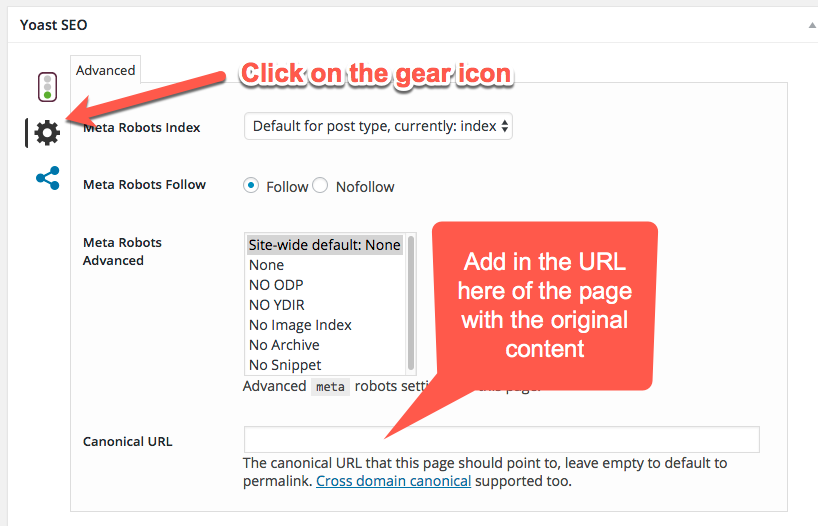
To find it in WordPress, go to our old friend Yoast SEO on the page in the WordPress admin and click on the gear icon. You’ll see a box that says “Canonical URL.” Fill in the URL of the actual content here. (The canonical url indicates where the original source of content is located.)
2. Duplicate meta descriptions
The meta description tag is a short summary of a webage’s content that helps the search engines understand what the page is about. It’s shown to users in the search engine results page (SERP).
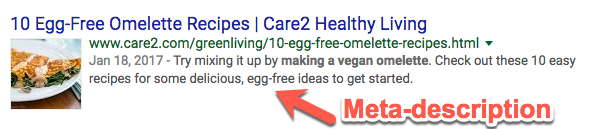
NOTE: In our sample study above, we discovered one website had a particularly high number of duplicate meta descriptions due to their website setup. We did not see this error often on different sites.
Solution: If you’re in WordPress, you’ll need the Yoast SEO plugin installed. Once it’s live, scroll down to the bottom of your post or page. There you’ll find the Yoast SEO fields.
Click on the snippet editor, where you’ll write a unique, relevant description of the page. This appears as the blue section below in the graphic below. If you don’t use Yoast, consult with your developer on where on the meta-description can be added.
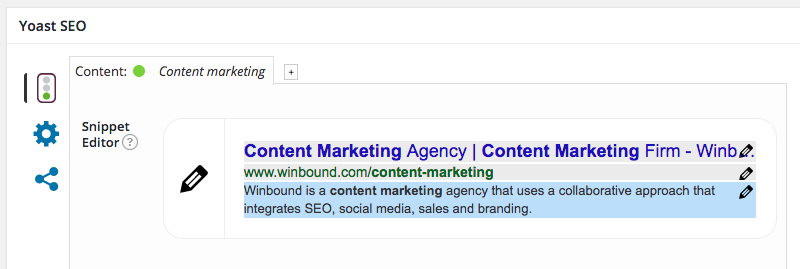
We recommend using the keyword you’re trying to rank for in the meta description. It adds to the user experience if the keyword appears in the meta description, because when they’re scanning the SERP they’ll be able to quickly identify their search term.
3. Broken internal and external links
Broken external links lead users from one website to another and bring them to non-existent webpages. There’s nothing quite as frustrating as running into a broken link, which translates into a poor user experience.
Solution: Once you’ve identified the broken link, you can either remove the link leading to the error page, or replace it with another link to a different resource.
Special situation: On some occasions, the link may work when accessed by a browser, but show up as an error on SEMrush’s audit. In this case, if you feel the link is critical, you can contact the website and let them know of the issue. Our recommendation would be to find another linking source.
4. Broken internal and external images
An internal and an external broken image is an image that can’t be displayed because it no longer exists, its URL is misspelled, or because the file path is not valid.
Solution: Replace all broken images or delete them.
Special situation: Just as in the case with broken links, on some occasions the image may work when accessed by a browser, but show up as an error on SEMRush’s audit. In this case, if you feel the image is critical, you can contact the website or your own webmaster and let them know of the issue.
No DIY – Errors where you’ll need a developer
We’ve given you some errors that you can correct with some time and a bit of knowledge about how to access different parts of your CMS. Some of these errors will require the help of a developer, unless you are comfortable working with the programming language of a website.

We’ve included SEMrush’s brief descriptions of each of the errors that showed up on our reports. There are a number of other errors, bulleted below, that didn’t show up, which we haven’t defined.
Mixed content (HTTP content on HTTPS pages)
In our analysis of these seven sites, 39% of the total errors could be attributed to mixed content. So what is mixed content?
Google wants websites to be secured with HTTPS. HTTPS stands for Hypertext Transfer Protocol Secure (HTTPS). It’s the secure version of HTTP, which means all communications between the browser and the website are encrypted.
(HTTPS is used to ensure you’re not being misdirected to a phone site, and is explained in more detail in this post on HowToGeek.com.)
With SEMrush’s “mixed content” error, you may have content from an old HTTP site that you are linking to from your HTTPS site. An example of this is images on a website. If you are linking to images hosted on an HTTP site, you will get an error. (This typically happens when you’re launching or relaunching a site.)
Your developer will need to move content from the old HTTP to your new HTTPS site.
4XX status codes
The 4XX error is an indication that a webpage cannot be accessed, and it’s typically the result of a broken link. In other words, if you have a link on your website to another page, but when clicked the link returns a “404 error” or a “403 error.”
Incorrect certificate name
If the domain name to which your SSL certificate is registered doesn’t match the name displayed in the address bar, web browsers will block users from visiting your website by showing them a name mismatch error, and this will in turn negatively affect your organic search traffic.
Page can’t be crawled (incorrect url format)
This issue is reported when SEMrushBot fails to access a page because of an invalid page URL. Common mistakes include the following:
– Invalid URL syntax (e.g., no or an invalid protocol is specified, backslashes are used)
– Spelling mistakes
– Unnecessary additional characters
Wrong page(s) in sitemap.xml
A sitemap.xml file makes it easier for crawlers to discover the pages on your website. Only good pages intended for your visitors should be included in your sitemap.xml file.
This error is triggered if your sitemap.xml contains URLs leading to webpages with the same content. Populating your file with such URLs will confuse search engine robots as to which URL they should index and prioritize in search results. Most likely, search engines will index only one of those URLs, and this URL may not be the one you’d like to be promoted in search results.
Page has WWW resolve issue
Normally, a webpage can be accessed with or without adding www to its domain name. If you haven’t specified which version should be prioritized, search engines will crawl both versions, and the link juice will be split between them. Therefore, none of your page versions will get high positions in search results.
Too large HTML size
A webpage’s HTML size is the size of all HTML code contained on it. A page size that is too large (i.e., exceeding 2 MB) leads to a slower page load time, resulting in a poor user experience and a lower search engine ranking.
Non-secure page
This issue is triggered if SEMrushBot detects an HTTP page with a <input type=”password”> field. Using a <input type=”password”> field on your HTTP page is harmful to user security, as there is a high risk that user login credentials can be stolen.
To protect users’ sensitive information from being compromised, Google Chrome will start informing users about the dangers of submitting their passwords on HTTP pages by labeling such pages as “non-secure” starting January 2017. This could have a negative impact on your bounce rate, as users will most likely feel uncomfortable and leave your page as quickly as possible.
Other issues that can occur:
- No viewport tag
- Pages returned 5XX status codes
- Robots.txt file has format errors
- Sitemap.xml files have format errors
- WWW resolve issue
- AMP pages have no canonical tag
- Issues with hreflang values
- Hreflang conflicts within page source code
- Issues with incorrect hreflang links
- Issues with expiring or expired certificate
- Issues with old security protocol
- Incorrect certificate name
- Pages couldn’t be crawled (DNS resolution issues)
- No redirect or canonical to HTTPS homepage from HTTP version
- Wrong pages found in sitemap.xml
The big question: How much does all of this matter?
That’s the great mystery in the world of content marketing and SEO. If you fix these errors, will you automatically jettison to the top of the rankings?
Our answer is no. We firmly believe that the best way to get top ranking on search engines is to produce high quality, relevant content that inspires inbound links. This is the fundamental law of how search engines work. They award high rankings to popular pages.
However, if you read through many of these errors, you understand they can lead to user frustration and a bad experience. If you have a bad page, people won’t link to it. So treat these SEO errors as part of the big picture. It’s the sum of these individual parts that will make a difference.
Find out how your content and conversion ranks with our interactive version of the Content Scorecard you can fill in yourself – no email required for download.

